Есть вещи, за которыми можно наблюдать бесконечно. Течение ручья, пламя костра, скандалы, интриги, расследования вокруг степенного закона в сетях. Итак, напомним, чем закончилась предыдущая серия нашего шоу. В начале 2018 года Анна Бройдо и Аарон Клаузет публикуют на arxiv препринт “Scale-free network are rare”. В этой статье на обширном эмпирическом материале они показывают, что на самом деле степени центральности у сетей обычно распределены лог-нормально, а не в соответствии со степенным законом. Иными словами, модель безмасштабных сетей, разработанная А.-Л. Барабаши и Р. Альтерт, может быть ошибочной.
Реакция общественности была разная. Кто-то посчитал это важным эмпирическим результатом, кто-то посетовал на недостаточное количество хороших исследований по сетям и жажду хайпа, а Альберт-Ласло Барабаши призвал коллег думать не об эмпирических подтверждениях, а о механизмах, формирующих социальные системы. Обсуждения в Твиттере были такими жаркими и насыщенными, что ученые уже не казались отстраненными обитателями башни из слоновой кости. Это была практически дуэль в прямом эфире!
Реакция общественности была разная. Кто-то посчитал это важным эмпирическим результатом, кто-то посетовал на недостаточное количество хороших исследований по сетям и жажду хайпа, а Альберт-Ласло Барабаши призвал коллег думать не об эмпирических подтверждениях, а о механизмах, формирующих социальные системы. Обсуждения в Твиттере были такими жаркими и насыщенными, что ученые уже не казались отстраненными обитателями башни из слоновой кости. Это была практически дуэль в прямом эфире!
 |
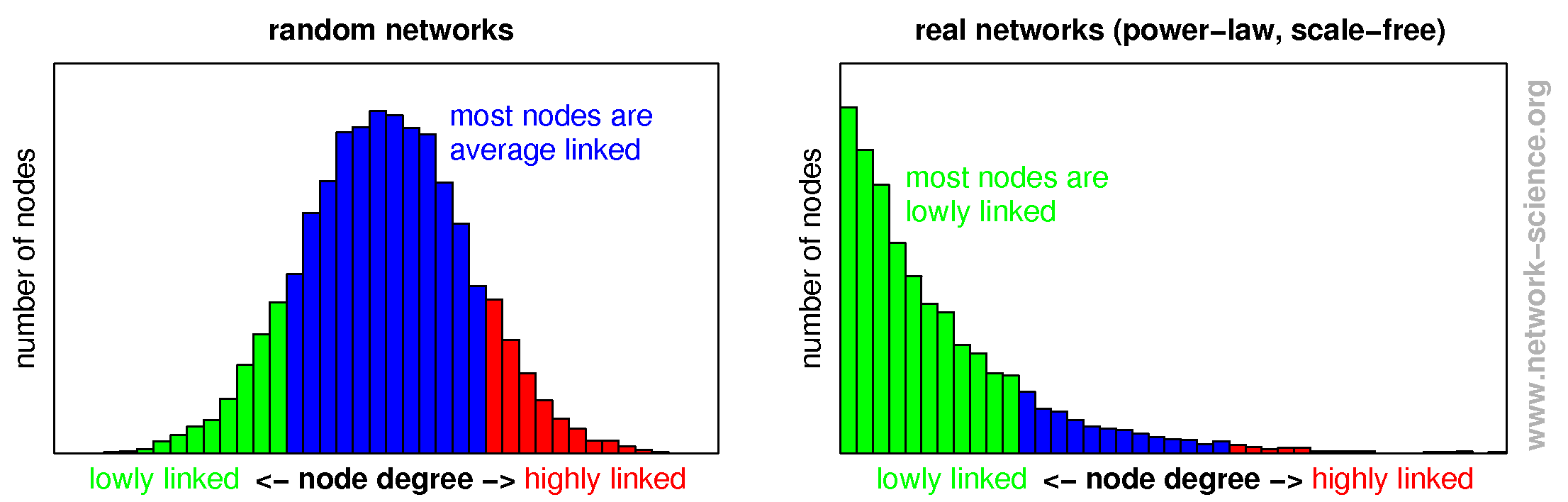
| Разница между случайными и реальными (например, социальными) сетями. В случайных сетях (слева) у каждого узла примерно одинаковое количество связей. В реальных сетях (справа) есть небольшая группа узлов с очень большим количеством связей, однако большинство узлов имеют достаточно малое количество связей. Источник изображения. |
Прошел год, но интерес к теме не утихает. Наконец, статья Бройдо и Клаузет вышла в Nature Communications. Петер Холм в своем комментарии для Nature Communications постарался увязать между собой и теоретическую модель Барабаши-Альберт, и эмпирические результаты Бройдо и Клаузета. При этом в конце 2018 подоспела статья (пока тоже на arxiv) про то, что “scale-free network well done”. Не будем удивляться, что большинство авторов статьи из Northeastern University, где работает и Барабаши, один из основателей модели безмаштабных сетей.
И вот, анализируя то, что происходит, хочется задать вопрос - почему это распределение вызывает столько дебатов? Ведь подавляющее большинство исследователей охотятся не за распределениями, а за объяснением того, что за механизм лежит в основе этих распределений. Барабаши и Альберт не открывали Америку, механизм предпочтительного присоединения в социальных науках известен давно. Это эффект Матфея, по которому распределение благ происходит неравномерно. В случае сетей - популярные люди с течением времени становятся все более популярными. И если эффект Матфея работает и в случае социальных, и других типов сетей, то это важный механизм. Однако могут ли какие-то отдельные особенности распределения и его хвостов опровергнуть этот эффект? В общем, продолжаем следить за сериалом и размышляем, будет ли в результате этой дискуссии выявлен еще какой-то интересный содержательный результат или все же нет. Не хотелось бы, чтобы именитые ученые тратили бы ресурсы на борьбу за амбиции.
И вот, анализируя то, что происходит, хочется задать вопрос - почему это распределение вызывает столько дебатов? Ведь подавляющее большинство исследователей охотятся не за распределениями, а за объяснением того, что за механизм лежит в основе этих распределений. Барабаши и Альберт не открывали Америку, механизм предпочтительного присоединения в социальных науках известен давно. Это эффект Матфея, по которому распределение благ происходит неравномерно. В случае сетей - популярные люди с течением времени становятся все более популярными. И если эффект Матфея работает и в случае социальных, и других типов сетей, то это важный механизм. Однако могут ли какие-то отдельные особенности распределения и его хвостов опровергнуть этот эффект? В общем, продолжаем следить за сериалом и размышляем, будет ли в результате этой дискуссии выявлен еще какой-то интересный содержательный результат или все же нет. Не хотелось бы, чтобы именитые ученые тратили бы ресурсы на борьбу за амбиции.


{kind=link}